TrafficLLM 复现 - Evaluation & Server
复现 TrafficLLM 中 Evaluation + Web Server(不涉及微调、训练)
论文简介
TrafficLLM 是中关村实验室崔天宇博士和清华大学徐恪教授、李琦教授团队共同发布的流量大模型工作。
TrafficLLM 是一种用于网络流量分析的通用LLM自适应框架。TrafficLLM介绍了一种通用解决方案,以回答如何通过增强对异构流量数据、跨不同任务的多模式学习以及网络流量的新环境的泛化性来实现鲁棒的流量表示。
论文:https://arxiv.org/abs/2408.10390
代码:https://github.com/ZGC-LLM-Safety/TrafficLLM/
研究背景
基于机器学习的流量分析方法具有以下局限性,导致其泛化能力较差:
- 跨各种任务的泛化。 在流量分析任务的每个子领域,现有的方法通常使用手工制作的特征和监督标签进行学习,为特定任务开发复杂的机器学习模型,模型很难在不同的任务之间共享。要涵盖所有任务的模型开发成本将非常庞大。
- 对未知数据的泛化。 当面对概念漂移和0-day攻击等未知的数据场景时,ML模型的泛化性能往往较差。
因此,开发一个更通用的模型对于提高不同任务和数据分布的泛化能力具有重要意义。最近,大型语言模型(LLMs)在许多复杂任务中表现出了出色的性能。得益于其模式挖掘、对未知数据的泛化以及跨不同任务的可复用性,LLM可以在各种下游任务中释放出非凡的能力,这激发了开发用于网络流量分析的专业大模型的可能性。
例如,LLM的模式挖掘和推理能力可用于学习流量数据中IP属性、标志和数据报长度背后的鲁棒表示。此外,泛化能力使LLM能够适应不同的网络环境和攻击场景。
因此,LLM可以作为一种更强大的ML模型,提供具有强大泛化能力的鲁棒流量表示。
LLM应用到流量分析的限制性
然而,流量领域的特性给实现LLM在流量分析任务上的泛化在三个方面留下了限制问题。
- 限制1: 对流量数据的异构输入的泛化。 流量数据由数据包中的结构化元数据(如IP和端口)和流中的统计特征(如流中的数据包长度和时间间隔)组成。然而,大多数LLM被认为是处理纯文本的专用模型,这与流量数据存在巨大差距。 在输入LLM之前,数据使用标准令牌生成器将文本转换为语言token。这些令牌生成器通常在大规模文本语料库上使用WordPiece和字节对编码(BPE)等算法进行训练。他们很少见过这些异构的流量数据。因此,LLM可能无法直接将流量数据转换为文本格式,并使用默认的令牌化方法加载它们。
- 限制2: 对跨不同任务的多模式学习的泛化。 网络流量分析涵盖了广泛的特定任务,例如在不同场景下检测和模拟攻击流量(例如MTD任务)。它涉及指令中不同任务特定的知识,以提示LLM进行不同的工作。此外,这些下游任务通常指向不同的网络环境,这涉及多种类型的流量特征模式(例如,加密应用程序分类(EAC)中的数据包长度序列和web攻击检测(WAD)中的HTTP请求头)。在进行多模式学习时,指令和流量模式的复杂性很容易使LLM感到困惑。
- 限制3: 模型更新扩展到新环境的泛化。 LLM的适应成本相当高,因为它需要用大量数据集训练大规模参数。然而,许多流量分析任务通常需要更新模型以应对动态场景,这是由应用程序版本更新(例如概念漂移)和攻击方法变更(例如APT攻击)引起的。LLM的高适应成本阻碍了模型能力在新场景下的更新。
TrafficLLM方法
 TrafficLLM是使用自然语言和流量数据的流量大模型微调框架。具体来说,TrafficLLM中主要提出了以下技术,以提高大型语言模型在网络流量分析中的实用性:
TrafficLLM是使用自然语言和流量数据的流量大模型微调框架。具体来说,TrafficLLM中主要提出了以下技术,以提高大型语言模型在网络流量分析中的实用性:
流量领域令牌生成
为了克服自然语言和异构流量数据之间的模态差距,TrafficLLM引入了流量领域令牌生成器标记化来处理流量检测和生成任务的不同输入以适应LLM。该机制通过在大规模流量域语料库上训练专门的Tokenizer,有效地扩展了LLM的原生令牌生成模型。

双阶段微调
TrafficLLM采用双阶段微调方案来实现LLM在不同流量域任务中的鲁棒表示学习。该方式在不同阶段分别训练LLM理解指令并学习与任务相关的流量模式,以此建立TrafficLLM对不同流量检测和生成任务的任务理解和流量模式推理能力。
主要关注LLM微调的两个挑战:
(i)如何帮助LLM理解与任务相关的自然语言,以确定应该执行哪个任务;(ii)如何学习不同任务之间的特定任务流量模式。
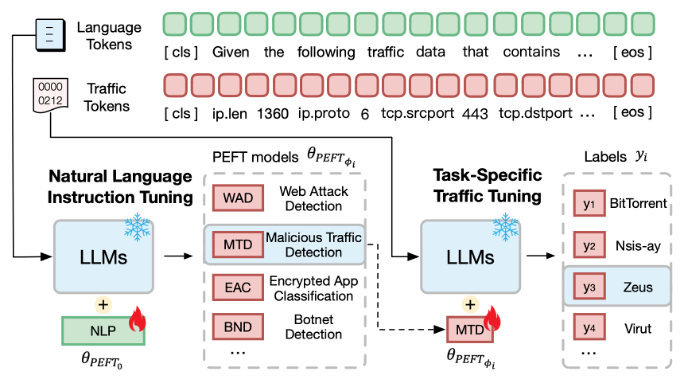
在双阶段微调的第一阶段,引入自然语言指令微调,将网络安全领域的专业任务描述文本注入LLM。第二阶段是针对特定任务的流量微调。在理解了任务后,迫使TrafficLLM学习下游任务下的流量模式。在这个阶段,使用流量数据和标签样本对对LLM进行微调,以在流量检测任务和流量生成任务下对流量表示进行建模。
基于参数有效微调的可扩展适应(EA-PEFT)
为了使LLM适应新的流量环境,TrafficLLM提出了一种具有参数有效微调(EA-PEFT)的可扩展自适应方法,以低开销更新模型参数。该技术将模型能力拆分为不同的PEFT模型,这有助于最大限度地降低流量模式变化引起的动态场景的适应成本。
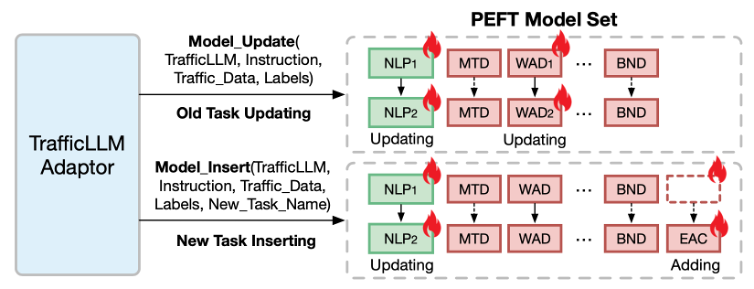
在EA-PEFT中,TrafficLLM Adaptor允许灵活的操作来更新旧模型或注册新任务。例如,当面对客户端版本升级(例如应用程序版本漂移)或攻击方法变更(例如HTTP请求体变更)引起的WAD任务中的流量更新时,Adaptor可以调用Model_update并提供新的EAC或WAD数据集来更新特定的PEFT模型。此外,TrafficLLM可以轻松添加新的流量分析场景。Adaptor可以调度Model_Insert来训练新的PEFT模型,并将其插入EA-PEFT框架中。在此基础上,TrafficLLM可以通过EA-PEFT的轻量级自适应方案轻松扩展到各种流量领域任务。
准备工作
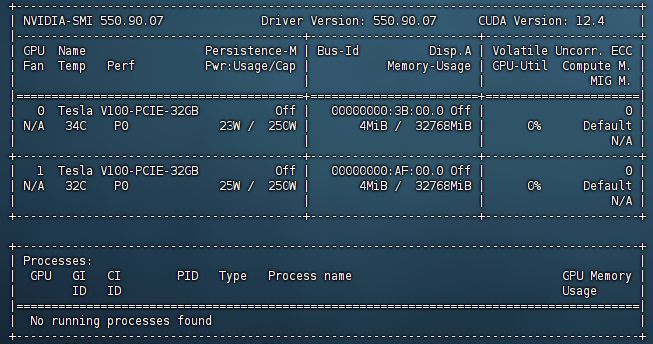
显卡配置:
配置环境
1 | conda create -n trafficllm python=3.9 |
下载数据集(这里只使用ustc-tfc-2016数据集)
1 | https://drive.google.com/drive/folders/1RZAOPcNKq73-quA8KG_lkAo_EqlwhlQb |
使用魔搭下载基座模型(这里为chatglm2-6b):
1 | pip install modelscope |
Evauation
evaluation.py 文件主要是用来评估 TrafficLLM 的效果。它支持检测任务 (detection) 和生成任务 (generation)。会根据不同任务类型(检测或生成),加载模型并对测试集进行评估,最终输出模型的预测结果以及评估指标(如准确率、精度、F1分数等)
具体代码解析:
- 导入相关库:
- 主要使用了
transformers库来加载和处理预训练模型。 sklearn.metrics用于计算评估指标如准确率、精度、召回率等。tqdm用于显示进度条,帮助跟踪任务的处理进度。fire库可以方便地将 Python 函数暴露为命令行接口。
- 主要使用了
test_set_to_prompt函数:- 这个函数用于将测试集的数据转换为模型需要的输入格式 (
test_prompts) 和对应的目标输出 (target_responses)。 - 它从
test_set中读取每个测试数据的instruction和output字段,并分别作为输入和目标。
- 这个函数用于将测试集的数据转换为模型需要的输入格式 (
td_evaluation函数:- 这是检测任务的评估函数 (
traffic_task == "detection")。它根据模型的输出和目标标签(target_responses),计算准确率、精度、召回率、F1分数,并打印混淆矩阵和分类报告。 - 通过
label_file中的标签字典,将模型生成的响应和目标响应映射到相应的标签。
- 这是检测任务的评估函数 (
tg_evaluation函数:- 这是生成任务的评估函数 (
traffic_task == "generation")。它将模型的生成结果按类别进行整理,并将其写入一个 JSON 文件,方便后续分析。
- 这是生成任务的评估函数 (
main函数:- 模型加载:根据
model_name和ptuning_path参数,加载指定的预训练模型。如果提供了ptuning_path,则会加载微调后的模型参数。 - 评估逻辑:
- 从
test_file中读取测试集,并通过test_set_to_prompt函数转换为输入和目标。 - 对每个输入(
test_prompt)调用模型的chat方法,获取模型的预测输出。 - 最后根据
traffic_task的不同,调用相应的评估函数(td_evaluation或tg_evaluation)来评估模型的性能。
- 从
- 模型加载:根据
- 命令行接口:
- 通过
fire.Fire(main),将main函数作为命令行入口。你可以通过命令行传递参数来运行该评估脚本。
- 通过
执行 Evaluation 的命令:
1 | python evaluation.py --model_name /Path/ZhipuAI/chatglm2-6b --traffic_task detection --test_file /home/ustc-tfc-2016/ustc-tfc-2016_detection_packet_test.json --label_file /Path/ustc-tfc-2016/ustc-tfc-2016_label.json --ptuning_path /Path/TrafficLLM-master/models/chatglm2/peft/ustc-tfc-2016-detection-packet/checkpoint-10000/ |
最开始会报错没有fire包,直接 pip install 一下就行了。
注意,这里需要配置基座模型的路径以及PEFT微调后的模型路径,是因为微调模型依赖基础模型提供的大部分权重和结构,所以在运行时需要同时加载两者。
总结来说:
- 基础模型(
--model_name) :提供了模型的完整结构和大部分预训练权重。- 提供了模型的核心能力(通用的语言理解、生成能力等)。
- 微调模型(
--ptuning_path) 只包含在特定任务上微调的少量参数(如前缀编码器的权重),这些参数必须在基础模型的上下文中才能工作。- 提供针对特定任务的增强部分,是对这些能力的专门调整和优化,用于在特定任务上表现得更好。
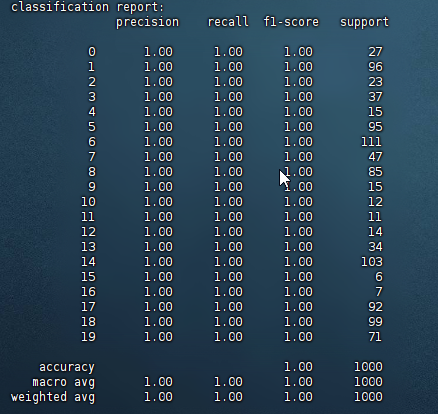
结果:
Web Server
先修改配置文件config.json,model_path改成自己下载的路径
1 | { |
使用 streamlit 运行 server:
1 | streamlit run trafficllm_server.py |

会给出一个访问地址,浏览器打开:

